GenAI-Powered Digital Threads Part 1 - A Novel Approach to AI Security
Updated March 24, 2024

Engineering organizations today are becoming increasingly data-reliant. All of our tools and stacks accrue large amounts of data that are distributed among tools and platforms––from our code and our repos, to our specs and requirements, CI/CD workflows, governance and policies, configurations across clouds, environments, and everything else. This growing amount of data is continuously used throughout our software development lifecycle (SDLC).
While organizations become greater data producers and consumers, organizations increasingly are becoming data-driven to make educated decisions with real business impact. However, much like Conway’s Law, as our teams grow more distributed, so do our systems, and ultimately as a byproduct, the data these systems produce. We have data scattered across our organization and stacks.
Why does this matter?
If our data were able to become more consolidated, with greater communication and visibility we could understand a lot more about cause and effect in our systems, and make decisions that apply to real problems and challenges we’re facing. For example, if we know which repositories are actually running in production, from a security perspective we can know which systems are actually exposed and pose risk to our organization. We can understand what is actually happening in our environments and make the right decisions at the right time.
This is because eventually as evolved as security tools have become over the years, these tools still treat all the parts they are intended to scan or monitor the same. This means that all repos are treated equally, all parts of the code, infrastructure, and anything else. This causes these tools to not only be very noisy adding a lot of complexity without having sufficient context, having a hard time distinguishing between real threats and alerts we can really just ignore (or not receive them at all, to begin with). This also creates a lot of cognitive load associated with managing security at scale –– and where it's valuable to invest effort, and what we can skip.
The data however is all there. It’s just a matter of connecting these distributed and scattered data points, to provide us with more helpful and context-based insights about our systems.
Borrowing from the World of Manufacturing (Again)
In the same way that DevOps borrowed assembly line concepts to streamline development through operations, by removing friction in workflows and pipelines, and adding much-needed automation, there is plenty more to learn from manufacturing to apply to technology concepts. Another concept popular in the world of manufacturing is digital threads.
This can basically be summarized as a closed loop between digital and physical worlds in order to help optimize products, people, processes, and places. (You can read more about this here). Connecting these different “endpoints” or threads enables you to have a much more holistic and comprehensive view of your business. This helps to answer the right questions.
Let’s take the example of a product defect. In order to track down why this product is being produced with a defect, by connecting data from different departments, disciplines, machines, and resources, it’s possible to understand whether the defect originated in the requirements and design, the Engineering, or in the execution and production. (Starting to see the similarities with our technology stacks?)
Knowledge Graphs for Technology Context
If we take a look at technology stacks, the place that would connect all of our disparate worlds of data is called a knowledge graph, which can be built into a graph database. A graph database is a tool that is very helpful in aggregating data from multiple data sources into a single unified place.
Below is an example of what an engineering knowledge graph would look like.
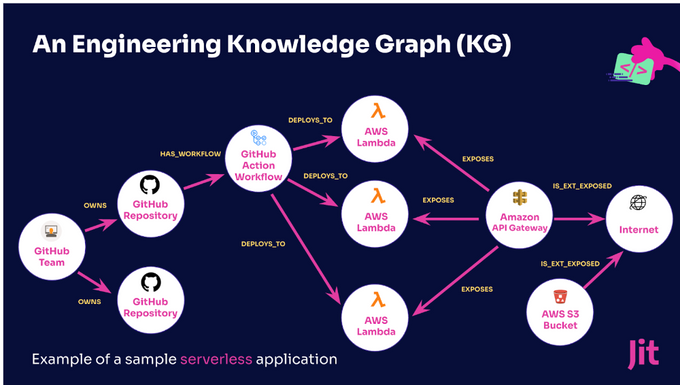
This is an example model of a service application that gives us a good understanding of the essential parts of our systems, and the data they produce, consume, and store. In this model, you can see that there is a Github team that owns several repositories. One of the repositories deploys a lambda function through a GitHub Action, where there is a workflow that sits in the repository, and is exposed to the internet because there’s an API gateway in the middle that exposes some endpoints.
With such a knowledge graph and diagram, it’s quite easy to distinguish that one repository is exposed to the internet and has a production impact, while the other does not. The hard part is to actually build this graph, particularly because as the graph grows, it’s harder to control the data and queries.
GenAI + Graph Database for Human Language Data Management
With generative AI (GenAI) becoming all the rage, with a diversity of applications across organizations, it’s no surprise then that another useful application for GenAI is querying useful digital threads compiled in a consolidated knowledge graph. If we’d like to be able to leverage the knowledge graph, without having to learn the entire syntax or language of the graph, as unfortunately there isn't yet one single standard, enter GenAI.
Why is GenAI interesting in this context?
Well, for starters, GenAI is smart. It’s particularly useful with being taught specific tasks, and evolving this capability. This means we can teach GenAI how to create queries for our graph database.
The knowledge graph provides us with the foundations to teach GenAI how to query it in human language. GenAI is known to have hallucinations and sometimes be creative with its answers. However, when coupled with a knowledge graph using structured data, it can have nearly 100% data accuracy.
Without this kind of accurate data together with relevant information for example about the type of environment (i.e. dev vs. prod), responses are rarely context-based, and largely vague or generic –– making understanding risk and mitigation much more difficult. This approach therefore basically brings the benefit of both worlds together, where we can have a way higher confidence in the data, but also ask and receive answers in human language, related to our very own stacks.
We can have GenAI orchestrate the querying of the model, which then, in turn, queries the graph, and ultimately can translate the intent from the knowledge graph created to useful and human language output. So, how do we do this without receiving raw JSON?
In this example we leveraged AWS Neptune coupled with GenAI –– this can be done with OpenAI or one of the models available in Amazon Bedrock (in our example, we picked the brand new Claude 3), where the value add of leveraging the AWS stack is that it comes with several models out of the box. The core of the graph database is built upon the open-source library Langchain, a library containing a module dedicated to query graph databases.
We’re Just Getting Started
This example was built and run pretty simply with a few out-of-the-box tools made available through the newly minted AWS suite of AI services, from Neptune to Bedrock, built to work natively together, and with the open-source AI ecosystem. These worked pretty well to help create a first sample app, and queryable knowledge graph in a digital threads approach, enabling the extraction of important data points in human language for greater context-driven security powered by AI.
In our next post, we’ll dive into the architecture and technical resources used to make this possible, walking through an example built upon AWS Neptune with Bedrock, and the open-source tools Langchain and Streamlit. This is a replicable example that will enable you to get started and test drive how you can and should do this at home (just mind the cost!), and gain better insights into your organizational security.
Stay tuned for the second more technical post in this two-part series.