AssumeRoleWithWebIdentity WHAT?! Solving the Github to AWS OIDC InvalidIdentityToken Failure Loop
Updated August 21, 2025

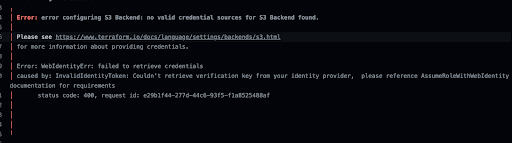
We encountered the InvalidIdentityToken error with the AssumeRoleWithWebIdentity method. This error occurred when running pipelines with an OIDC provider for AWS. We went through a whole process of researching and ultimately fixing the issue. We decided to give a quick runthrough in a single post of how you can do this too.
How many of us have encountered all kinds of [.code]CrashLoopBackoff[.code] or other random error messages, and start to go down the Stack Overflow rabbit hole, only to hit a wall?
In our case this occurred with the [.code]AssumeRoleWithWebIdentity[.code] that started throwing the [.code]InvalidIdentityToken[.code] error when running pipelines with an OIDC provider for AWS. We went through a whole process of researching and ultimately fixing the issue for good, and decided to give a quick runthrough in a single post of how you can do this too.
So let’s take a step back and provide some context to the issue at hand, when you’re likely to encounter it, and ways to overcome it.
Web Applications and AWS Authentication through the OIDC Plugin
When companies work with AWS with third-party resources, they need to create a “trust relationship” between AWS and the service to ensure the resource has the necessary permissions to access the AWS account. To do so, the OpenID Connect (OIDC) plugin, a simple identity layer on top of the OAuth 2.0 protocol, is a commonly chosen method for doing so.
For us, the service at hand was Github, where the OIDC authentication was configured in Github, to provide our Github repo the required trust relationship to access our AWS account with the specified permissions through temporary credentials, in order to create and deploy AWS resources through our CI/CD process. We basically had a primary environment variable configured ("AWS_WEB_IDENTITY_TOKEN_FILE"), which then tells various tools such as boto3, the AWS CLI or Terraform (based on the relevant pipeline) to perform the [.code]AssumeRoleWithWebIdentity[.code] and get the designated temporary credentials for the role to perform AWS operations.
Random Failures with Esoteric Error Messages
The [.code]AssumeRoleWithWebIdentity[.code] error manifests itself mostly around parallel access attempts, and how the various AWS interfaces are able to authenticate, as well as run and deploy services. We started encountering this issue when running our pipelines for deployment, and attempting to authenticate our Github account to AWS via the OIDC plugin. This is a well-known (and widely discussed) limitation for authentication to AWS for web application providers. In our case it was Github, but this is true for pretty much any web application integration.
At first this error would randomly fail builds, with the [.code]InvalidIdentityToken[.code] error, which would only sometimes succeed on reruns. At first we ignored it, and just assumed it was the regular old run of the mill technology failures at scale. But then this started to happen more frequently, and added sufficient friction to our engineering velocity and delivery, that we had to uncover what was happening.
So what was happening under the hood?
Our design consisted of a method to retrieve the token from AWS, where we then used the token in order to try to connect to AWS. Where this fails is with the threshold that AWS enables for multiple parallel authentication requests, along with the very low Github timeout for response. The tool chain we were using essentially tried to access this token simultaneously many times, and this caused the authentication access to fail upon throttling of the resources.
Fixing the InvalidIdentityToken error with the AssumeRoleWithWebIdentity Method
Overcoming this issue was a concerted effort, which began with even understanding what triggers this issue to begin with and how to get to the root cause, and then solving the issue ––particularly since when authenticating to AWS there is usually a canonical order, for example, first the environment variables, to ensure the environment runs as it should with access to the relevant keys and private information.
We found that the current method we were using of a temporary token from the provider for direct authentication access, was clunky. There is no way to use this method without creating a system of retries, which is never robust enough when it’s out of your control, and not all of our tools supported, either.
Therefore, we understood a more stable method was required, we would need a way to control the token calls for authentication. By doing so, we would be able to ensure retries until success, so that failures due to inherent limitations can be avoided or at the very least retried until successful.
First and foremost, let’s talk about our tool chain. Not all the tools we were using (boto3, Terraform), have the logic or capability for retries, and this where we were encountering these failures. With multiple pipelines running simultaneously, all using the temporary access token method for authentication, we quickly reached the threshold of authentication and access.
In order to enable parallel access we realized we were missing a critical step in the process to make this possible. The actual recommended order to make this possible would be to retry the [.code]AssumeRoleWithWebIdentity[.code] until success, and then set the environment variables upon successful access (based on the docs these include : AWS_ACCESS_KEY_ID + AWS_SECRET_ACCESS_KEY + AWS_SESSION_TOKEN). Another equally critical piece to make this all work was to provide a longer validity window for our token, in our case we set the expiration to 1 hour, and the last and most important part, by performing the retry ourselves.
Once we understood the process we needed to make parallel access work, we started to do some research, and happened upon a Github Action that basically does this entire process end-to-end for us, all the way through configuring the environment variables under the hood for the temporary credentials. The added bonus is that this Github Action prevents Terraform from assuming the role, and simply uses the credentials that were set (that are now valid for 1 hour). Another advantage of using this Github Action is that it also addressed a known exponential backoff bug that was fixed in January.
By setting these environment variables that are valid for up to an hour, this adds stability to the system, as the tokens are now AWS tokens and not unstable OIDC tokens, basically bypassing the need to assume a role directly for authentication vs. the provider.
Similar logic can basically be applied to any application that uses the OIDC plugin, that encounters such issues, even those that we couldn’t leverage the excellent gem of a Github Action for. We borrowed from this, and wrote our own code that replicates similar logic for non-Github applications to achieve similar stability. See the code example below:
To wrap up, what we quickly understood is that even with a small feature change from single to multi-region, that suddenly required parallel access, a process that worked perfectly fine for sequential access, wasn’t the best fit when we started to grow. This naive design broke down at scale and required us to unpack the complex logic happening under the hood.
When we encountered this issue we were searching for a tutorial just like this one to help us resolve the issue quickly, so we hope you found this useful and can save some of the time and effort it took us to resolve the issue