Defining DORA-Like Metrics for Security Engineering
Updated September 17, 2024

AI Summary
By implementing security metrics that are as demonstrable as uptime and performance SLAs, DevSecOps leaders can showcase their engineering prowess in security.Measuring security in terms of MTTR, MTTD, Detection rate, Exposure window, as well as velocity, coverage, and uptime, can drive its evolution and development, providing similar automation, observability, and capabilities available in engineering.We encourage you to read this informative article, written by Daniel Koch, our very own VP of engineering at Jit.io Check it out.
Defining DORA-Like Metrics for Security Engineering
We’ve all seen the DevSecOps diagram that looks like this.
Figure 1
But if we look closely, there really is no place in this diagram that talks about remediation at all. Some put this under “operate,” but that’s only partially true (and largely only focuses on issues already in production).
While security tries to find its way into this diagram (in this case, it appears as the purple arrows
When it comes to legacy security, the truth is, the practice pretty much stops at remediation. Traditional security is about finding issues, not resolving them, and this is a tragedy in high-velocity engineering organizations. This creates friction that has become the blocker to enabling security to be a first-class citizen in true engineering processes.
We’ve spoken about this in previous posts and about how engineering organizations need to develop a fix-first mindset when it comes to security in much the same way they do this for operations. I’d like to be even bolder than that and posit that security would benefit from the same level of transparency available today with regard to service-level agreements (SLAs) and operational posture for other engineering disciplines.
DevOps didn’t only introduce the culture and processes to enable the level of automation and velocity we have today, it also shifted the focus to radical transparency through its disciplines of monitoring, observability and measurement through SLAs and service-level objectives (SLOs). Today, any SaaS or service that prides itself on its high availability and elite engineering capabilities has an uptime page. They want you to know when things are great and also have immediate information when things go down as well.
They’ll share post-mortems to ensure users know that they understand what went wrong. And everyone fails, from Roblox to Meta. They’ll quantify in numbers the amount of time their service was down and dig down into the nitty-gritty of what went wrong under the hood. But the important part is the timing — they’ll do all of this after the fact. POST mortem.
There are two incredibly important learnings that DevSecOps can take from the DevOps world. The first is the suspension of fear. There is a consensus in the security world that you don’t expose your vulnerabilities and stack to anyone. No one can know your real-time security posture, even clients that security issues may impact. Clients are completely dependent on the company to disclose any breaches or security vulnerabilities unless it is done by a third party without their knowledge.
There is, of course, logic to this. If a malicious person were to discover you are using a certain service or tool in your chain that has an active zero-day vulnerability disclosed, they could use this to exploit your systems. However, this same secretive mindset is also true for internal information sharing. There is little to no internal transparency around security metrics.
The other part of the equation is the actual method in which infrastructure engineers operate during downtime or any other time. They are head-down on fixing the issue immediately, and they analyze what went wrong later in order to improve. This is where security can benefit from a similar approach. Whereas much of the current processes and culture focuses on discovery, they need to move to a culture of getting stuff fixed.
Demonstrable Measurable Improvement in Security
Security is lacking a measurable process of security improvement that will be beneficial to engineering as well as security owners and end users. By measuring the places that map directly to the same metrics that books like “Accelerate” have solidified to identify elite engineering — speed and safety — you can have similar DORA-like metrics for security. Security to date has been considered a hindrance to high-velocity engineering.
However, the flip side of this is that engineering managers already understand quite deeply that security can no longer be left behind, and so they’re stuck figuring out how to make clunky tools work.
What’s more, the legacy security practice of annual audits and other point-in-time security checkups has proven to be pointless for true security assurance. Engineering moves much more rapidly, and the minute after point-in-time reviews are over, they are basically irrelevant.
The security conversation needs to move from annual compliance, a nice to have and not the end goal, to a continuously measurable process of improvement in security posture and SLAs.
With operational availability now essentially publicly available, built programmatically and publicly shared, security is capable of much the same thing — and it is ready to evolve as a practice and discipline.
Measuring security with a focus on:
- Increased velocity (yes it’s possible)
- Coverage and uptime
It will enable security to evolve and level-up, unleashing similar capabilities, automation and observability made possible for engineering.
Increased Velocity
It sounds almost like the antithesis of security to enable increased engineering
velocity, but this will soon be the case. If security is embedded early in engineering processes — and there are plenty of excellent DevSecOps and open source security tools that make this possible — it will be possible to remediate issues early, in pre-production, and not grind the entire engineering team to a halt when issues are discovered in production requiring all hands on deck for remediation.
When you start to measure how quickly issues pop up in production, and then also how quickly they are remediated, you can also achieve a programmatic way of measuring your security. This is what we consider the security change failure rate — security CFR — as well as the mean time to remediate — security MTTR and more. But it can get even better than this.
Coverage and Uptime
The security CFR and MTTR talk about how frequently we introduce security issues into production and are remediated, but truly elite engineering is measured in the gaps between these incidents. It’s measured in uptime and coverage, not in downtime. This safety is essentially the enabler of the two other critical metrics that quantify speed — deployment frequency and lead time for changes. When you get to a level where you trust your security engineering tools that are so well-integrated into your engineering processes, where you can detect and remediate issues before they ever reach production, you will minimize the need for operational and engineering disruption. This is truly the sweet spot.
We’ll be able to demonstrate ongoing continuous security improvement that doesn’t delay software delivery cycles while providing the security assurance required by engineering organizations today to deploy rapidly, and not be held back by out-of-process security reviews. By making security programmatically demonstrable just like uptime and performance SLAs, DevSecOps owners will be able to tout this security engineering excellence in-product, in standups and dailies. Auditors won’t need to test this once a year; they’ll be able to have a constant, and continuous indication of security coverage and “uptime.”
Concrete Examples of Measurable Security
I’d like to take this from high-level theoretical to actual, practical examples that need to become the standard for measuring security in order for engineering to level up and embed security into engineering processes.
Escape Rate AKA Pull Requests Merged with Security Findings
One thing we’ll often see in high-velocity engineering organizations is the need to ship software rapidly and often, and this can often come at the expense of security, even when it is flagged and documented through the right tooling.
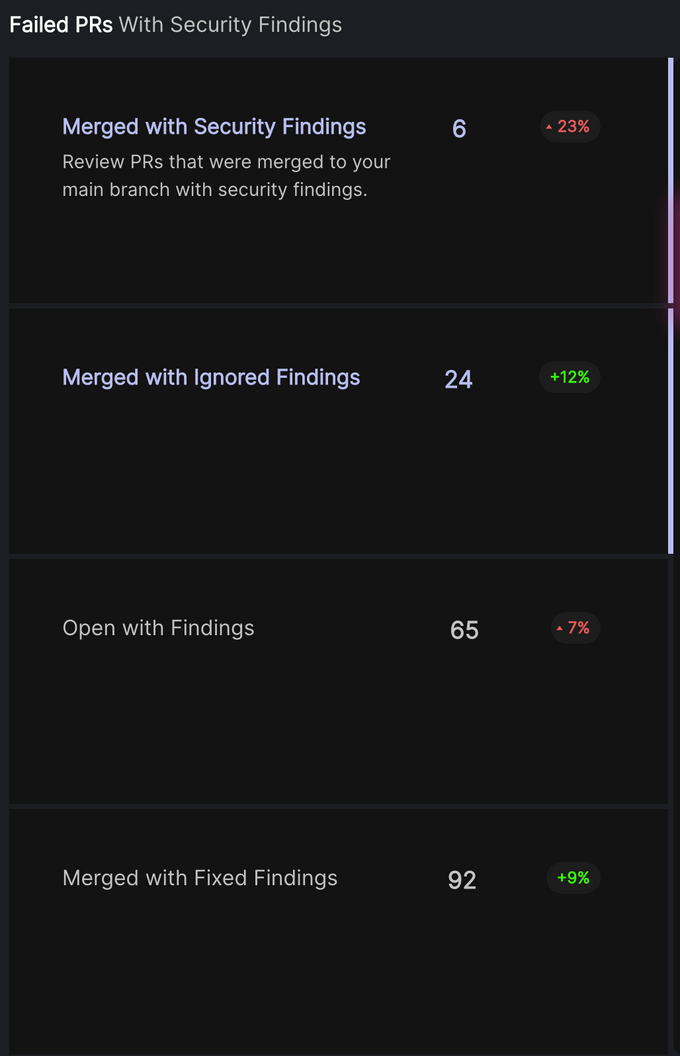
If we actively measure how often and how many pull requests (PRs) are merged with security findings, we can then begin to measure security improvement in the short-, mid- and long term as our security posture and culture evolve. We want to get to a place where we are one step ahead of security and merge vulnerabilities with clear remediation suggestions before they reach production.
Time to Full AppSec Coverage
Another important metric to examine is the “Time to Full AppSec Coverage,” based on your specific stack. Today, we’ll often see, even with security-minded engineering organizations, that it can take weeks, months and sometimes even a year to integrate all the required tooling to achieve full end-to-end of engineering stacks (and especially as this is a constantly moving target with new technologies being introduced).
With an open and pluggable DevSecOps orchestration engine, this becomes infinitely easier. Integrating the required tools and gaining relevant coverage comes with a lot less friction and can be achieved much more rapidly. Hopefully integrating DevSecOps tools becomes as simple as any other dev tools quickly adopted by engineering teams.
This becomes possible when you’re natively integrated in CI/CD pipelines. Discovery becomes embedded into developer workflows by identifying in the existing repositories and stacks the different languages, technologies and even third parties in use. Once we can easily identify and understand their current AppSec coverage, implementing the tools and processes to provide greater coverage is one pull request away.
Security to Match our CI/CD Systems and Pipelines
It’s not a question of whether this will happen. Security must undergo this transformation and level up. Our security systems need to match our CI/CD, pipelines and engineering systems and align with all of the same practices to remain relevant.
Developer experience is becoming central both in the products we deliver and the ones we want our engineering teams to use, and this mindset needs to make its way into security engineering as well. Developers will only align with products that enable speed with safety. Only once we know how to deliver this through security-as-code and dev-native security, while also measuring and sharing this knowledge, will we be able to evolve as an industry.




