Designing Secure Tenant Isolation in Python for Serverless Applications
Updated March 5, 2024

About
This content is brought to you by Jit - a platform that simplifies continuous security for developers, enabling dev teams to adopt a ‘minimal viable security’ mindset, and build secure cloud apps by design from day 0, progressing iteratively in a just-in-time manner.
Originally posted: https://www.infoq.com/articles/serverless-tenant-isolation/
Key Takeaways
- SaaS applications often choose a multi-tenant architecture for better resource utilization
- Multi-tenant architectures require robust tenant isolation design and implementation, to avoid data leakage between tenants
- Architecting tenant isolation for serverless-based applications differs significantly from other existing cloud-based designs
- The Pool isolation model was selected - by pooling the data, and creating IAM permissions by tenant to access the relevant data
- Passing credentials all the way to the data layer, without conflicting with application logic proved challenging, and required an elegant solution built upon the ContextVars library to take this from design to implementation
Software as a Service (SaaS) has become a very common way to deliver software today. While providing the benefits of easy access to users without the overhead of having to manage the operations themselves, this flips the paradigm and places the responsibility on software providers for maintaining ironclad SLAs, as well as all of the security and data privacy requirements expected by modern cloud-native organizations. This has also been the driver behind adopting resource- and cost-effective architecture patterns such as multi-tenancy.
Jit, a SaaS platform for building minimal viable security through automated declarative security plans, was designed and architected to serve many clients and users at scale. Therefore, one of the major characteristics of our system’s architecture is its multi-tenancy support. However, multi-tenancy comes with its own set of security implications. As a security company, being able to isolate and secure our tenants was important from day one, to have a robust, secure, and scalable multi-tenant architecture.
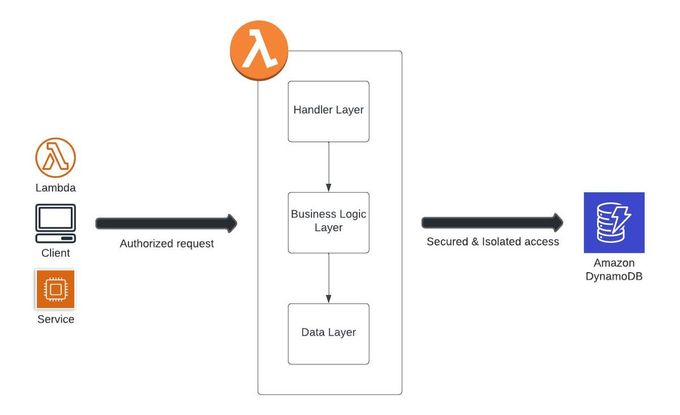
Figure 1: Jit Tenancy Architecture
While there are many posts on the web about how to architect tenant isolation, the last mile is ultimately always specific to your tech stack. Here at Jit, our stack is largely Python and serverless, with a DynamoDB backend for read and write operations. When looking for a good way to isolate tenants for this architecture, there were plenty of excellent posts about Python + DynamoDB, but there was less material to be found about passing credentials to the data layer with serverless architecture, and I thought I’d share how we designed and implemented multi-tenancy for a cloud native serverless stack.
Challenges with Multi-Tenancy at Scale
I’ll start with the basics. Many SaaS products today choose to architect their systems as multi-tenant for better resource utilization. Multi-tenancy means that different clients share infrastructure resources, and are essentially logically split through a system of “tenants,” where each tenant is allocated to a single client. However, like any system based on shared resources, there are benefits and also challenges.
The main problem with multi-tenant systems is that if data leakage prevention between tenants isn’t explicitly designed from the early stages this can have grave consequences in the long term. Data leakage can happen between tenants from anything as simple as not having strict enough code or a developer’s error, to a specific malicious attack––where an attacker gains access to one compromised token and then exploits the system to escalate privileges and gain access to additional data.
When considering the methods for mitigating such a scenario there are two primary ways to do so. One way is the Silo isolation model, basically complete isolation, by creating a full and separate stack per tenant in the system, and therefore preventing any pooled or shared resources. While this solution is very secure, it’s not very scalable or resource efficient, and it is costly. We realized this wouldn’t be a good long-term architecture for the system.
The other option and a commonly chosen pattern in SaaS systems is the Pool isolation model—creating a resource pool (a shared table, for instance), and isolating the data through a specific IAM (identity and access management) role that grants access to relevant data per tenant. This means that you will pool the data by containing it in a shared table, but you will limit the access through a verified role.
Architecting Tenant Isolation for Serverless Applications
To enable isolated access, we’ll dynamically generate credentials to be used when accessing a DynamoDB table. A typical JWT (JSON Web Token) will consist of a tenant ID, which can be used as the tenant ID to limit access.
Figure 2: Tenant Isolation Architecture
To be able to generate the credentials, we’ll need to create a dynamic policy that limits the access to the DynamoDB table by a specific pattern, and use it to assume a role upon user request. When the user is verified and the dynamic role is created, this will grant access and the querying of the DynamoDB table, provided that our table’s primary key (PK) is arranged by tenant.
Generating the dynamic policy
Given our PK is arranged by tenant, and a DB item might look something like this:

We would like to generate a policy that will allow us to perform actions solely on items that belong to a specific tenant. To do so, we’ll make use of the statement condition "dynamodb:LeadingKeys" that will approve only items whose key starts with a specific given value. This is what that looks like in practice:
def generate_dynamodb_policy(tenant_id):
- In "Action" we should provide an array with the DynamoDB actions we want to allow in this policy. This can be "dynamodb:*" (for all DynamoDB actions), or any specific set of actions.
- In this example we can see two options for leading keys. The first is for cases like in our DB item example, and the second is for keys that consist of multiple attributes (e.g. “TENANT#<id>#NAME#<name>”).
Using policy to generate session credentials
In the next step we will use the generated policy to assume a role, and use the returned credentials to access the DB:
import boto3
Important note—In order for this to work, we have to:
- Predefine an IAM role to assume in our AWS account. This role should have broad DynamoDB permissions and a trust relationship with our lambda’s role.
- Grant our lambda with permissions to assume the predefined role. We can declare this under provider.iamRoleStatements if using the serverless framework.
Using credentials in our lambda function
Now we can use the credentials we just created to initialize a DynamoDB table object:
import boto3
After we figured out how we intend to secure the table data, the next question that arose was how exactly to do this with our specific stack—which had its own inherent complexities.
We understood that upon initialization of the lambda function’s execution, we would need to generate the dynamic policy, assume the role, and get the credentials to be used when querying the DB. However, this proved easier in theory than practically applied.
First, let’s understand why it’s important to generate the credentials in the handler layer before the handler’s code starts running (and not inside the data layer for example). One reason would be that the lambda event contains a JWT header with a payload that ultimately consists of a validated tenant ID. We want to use that tenant ID for the credential generation in the most secure way, but still not have to pass the event object all the way down to the data layer. Another reason would be that the data layer is common code, and should not contain any external logic. The handler layer seemed like a perfect candidate for such a setup.
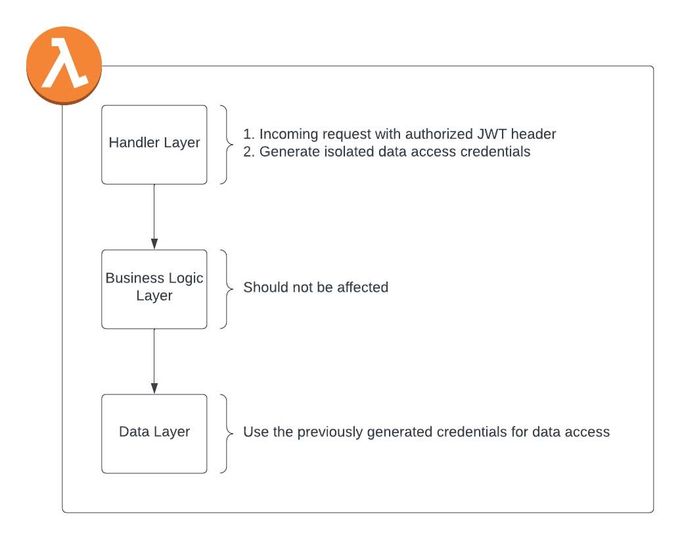
Figure 3: Tenant Isolation Layers
The first part was the easy part—we implemented the dynamic policy creation with a (Python) decorator. This can be implemented above the handler or even through middleware––however, the most important thing for the policy aspect is that it runs before the lambda code to create the credentials before the handler’s execution.
Passing the Credentials to the Data Layer
The harder part was figuring out how to actually pass these credentials all the way to the data layer, which I didn’t find much about in my research. We came up with a few ideas for how to solve this issue, each with its own set of challenges.
The first solution we thought about was to pass the credentials through the request context. In this way, we would have to pass this data from the function handler, through the business logic layer, all the way through to the data layer. This posed a problem of having to go through the business logic layer that doesn’t require these arguments, and could possibly cause interference or conflict with the logic layer of our service. This felt too risky to us.
Another solution we explored was declaring a global variable, but this would essentially conflict with the lambda runtime that shares the global state. This means that multiple executions of the same lambda can conflict and interfere with the execution of the function. The outcome could be that if multiple requests come in simultaneously by two different tenants that the function could potentially leak one tenant’s credentials to the other (the exact situation we were looking to avoid in the first place). The flip side also is if the wrong credentials are received, the requesting tenant will receive errors when trying to query their data, as it will have the wrong tenant ID and will not be verified.
So that wouldn’t do either. Back to the drawing board.
ContextVars to the Rescue
Then we discovered a standard Python library for just this use case. It’s called “contextvars” and it’s available for Python 3.7 onward (with some support for earlier versions through open libraries). This library enables us to save global vars inside a specific runtime context. Using this library, we can create a new running context for every incoming request, and save a value on a global var, which will only be available within that context. Then, when we access this global var under the same context’s run, we’ll get our relevant encapsulated data.
For more detailed information please refer to the contextvars documentation.
This solved the issue of the global invocation of environment variables and enabled context-specific invocation for each request.
In the following snippet, we are implementing a decorator, which creates a new context and runs the lambda handler under that context. In this way, any access to dynamodb_session_keys will be bound under the invocation context and will encapsulate one invocation datum from another.
"""
Now it was possible to have our decorator create the dynamic policy and credentials, and save these under the context-bound global var, ultimately creating an export and making it possible to receive the context-bound credentials inside the data layer.
This is how we access the credentials from the data layer:
"""
And then hooking it all together into our handler file:
"""
This solution provided a more scalable, robust tenant isolation for our Python/lambda based architecture, without conflicting with our service’s business logic layer, nor compromising the data upon multiple requests. Using Python capabilities like decorators and contextvars, provided us with the ability to create a solution that is tailored to our specific use case, with minimal to no conflict with our existing code base, when compared to other valid solutions.
You can find the full example in this github repository.