DORA Metrics: Delivery vs. Security
Are DORA metrics the ultimate key to improving delivery AND security in DevOps? Not always.
Updated September 17, 2024

AI Summary
When it comes to software development and delivery, developers can never be fast enough. Because of that, measuring performance is key to addressing the constant pressure to deliver at high speeds.
"One accurate measurement is worth a thousand expert opinions." - Grace Hopper, computer scientist
Enter DORA metrics. The DORA core metrics consist of four key traits for evaluating DevOps teams’ performance and helping them achieve higher performance rates.
This article will look into the following:
- What DORA is
- Overview of four DORA traits
- Benefits and challenges of DORA metrics
- DORA metrics' impact on delivery vs. security
Meet the Expert
Ariel Beck is a Software Architect at Jit.io. He holds a B.Sc. in Computer Science from the Academic College of Tel Aviv-Yaffo. He has over 10 years of experience as a software architect in various fields and technologies, focusing on cloud-based solutions.
Ariel is skilled in Kubernetes and AWS serverless technologies and has led multiple teams in adopting microservices. He is dedicated to helping JIT build a scalable and well-architected solution.
What Is DORA?
DORA, the DevOps Research and Assessment, was originally a startup that provided assessments and reports on companies’ DevOps efforts. DORA was acquired by Google in 2008.
After six years of research and 31,000 data points, DORA is one of the longest-running, academically rigorous research programs. Using behavioral science, DORA's studies were able to highlight ways to make software development and delivery more efficient.
Through DORA metrics, DORA strives to help DevOps teams achieve high performance and improve capabilities.
» Find out how to define DORA-like metrics for security engineering
Overview of DORA Metrics
DORA metrics' core objectives are assessing and improving the performance of DevOps teams. The four key metrics are:
- Deployment frequency
- Mean lead time for changes
- Change failure rate
- Time to recovery
The first two metrics, deployment frequency and mean lead time for changes, measure the speed aspect. The change failure rate and time to recovery evaluate the stability in DevOps.
Using the performance benchmarks for each metric and analyzing how teams score in these four variables, the teams can be categorized into:
- Elite
- High-performing
- Medium
- Low-performing
Let’s explore each of these metrics in more detail.

Open ASPM Platform
App + cloud security that developers love
Read reviewsCoverage
SAST, SCA, secrets detection, IaC scanning, DAST, CSPM, and other product security controls
Easy for developers to adopt
Automated scanning within dev environments
Automated prioritization
Automatically surface exploitable vulnerabilities in production
Easy onboarding
Integrate Jit with your Source Code Manager to enable one-click activation for all tools
Brief overview
Jit empowers developers to consistently and independently resolve vulnerabilities before production with automated scanning in their environment.
Rather than requiring developers to scroll through long vulnerability backlogs in different UIs, Jit provides immediate feedback on the security of every code change within GitHub, GitLab, or VsCode.
As a result, Jit makes it exceptionally easy for developers to adopt regular security testing within their environment.
Key features
- Unified SAST, SCA, secrets detection, IaC scanning, CSPM, DAST, and other product security controls
- Unified execution and UX for all security tools
- Fast and automated scanning within GitHub, GitLab, or VsCode
- Jit’s Context Engine determines whether a vulnerability is actually exploitable in production to prevent alert fatigue and long backlogs of irrelevant vulnerabilities
- Unified monitoring and reporting
Pros and cons
Easy for developers to adopt
Unifies all tools
Automated vulnerability prioritization based on runtime context
Fast onboarding across all repos
Not open source
4 Key Dora Metrics Explained
1. Deployment Frequency
Deployment frequency measures how long it takes for your organization to get a change in production, i.e., how often the code is successfully released to the end user or deployed to production.
It is an essential DORA metric that evaluates the average throughput and displays the cadence of delivering value to the client.
Continuous development and changes shipped in small, ongoing batches are essential for achieving a high deployment frequency.
A higher deployment frequency also means shipping values to the customers more quickly. The benefit of this is in consistent feedback and higher customer retention.
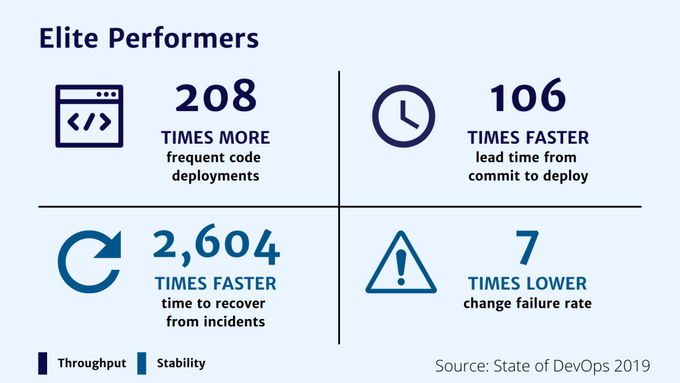
DevOps elite performers strive for continuous delivery every day, whereas low-performing teams often score a deployment frequency of about once per month.
2. Mean Lead Time for Changes
The mean lead time for changes is the time it takes the DevOps team to get a committed code to a successfully running state within the production state.
This DORA metric helps DevOps teams determine how healthy their cycle time is and if the team can handle a higher volume of requests. For instance, average-performing teams take about one week to complete this process, whereas elite performers often do it in less than a day.
A team's lead time is often diminished by having separate test teams and shared test environments.
To identify and narrow the obstacles to improving your DevOps teams' lead time, analyze the different metrics in the development pipeline: time to merge, time to open, and time to first review.
3. Change Failure Rate
Bugs and failures are inevitable in a production environment with frequent changes. The change failure rate is a percentage value derived from the total number of deployments to the total number of failures ratio.
As a metric, the change failure rate shows the number of changes that count toward failures in production. The failures can be failed deployments, rollbacks, or incidents that require fixing.
Maintaining a low change failure rate means your DevOps team delivers quality code.
The elite, high, and average performers score around 0 to 15% change failure rates. Low performers often have a change failure rate of about 40% to 65%.
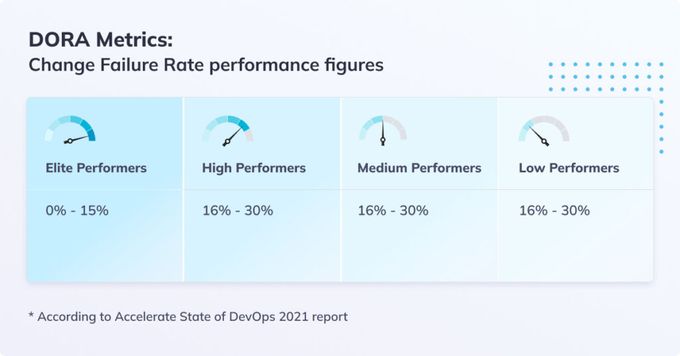
Teams with more automation tools tend to have lower change failure rates since their development process is more established and consistent. The lack of automation, on the other hand, leads to a higher change failure rate and loads of small changes to implement.
4. Time to Recovery
Time to recovery is a critical metric that directly impacts DevOps stability. It is expressed as the time needed to restore the service when a defect, accidental outage, or service impairment occurs.
The mean time to recovery (MTTR) for elite teams is typically less than an hour, whereas low-performing teams can take from one week to one month.
By improving observability and monitoring in DevOps teams, the failures are identified and recovered faster.
How Dora Metrics May Help Your DevOps Team
Any company requires tangible goals and evidence to achieve stability and progress.
DORA is a starting point in determining your team's current performance.
The metrics provide insights and evidence of the team's performance measured against the industry standards. These, in turn, help the DevOps leads identify bottlenecks to achieve high performance and stability and ultimately improve decision-making.
Challenges of DORA Metrics
Each enterprise is different, and its metric goals, problems, and delivery environments vary. Despite their many benefits, each DORA metric is a mixed blessing and doesn't tell the DevOps story from a broader perspective.
To avoid being blindsided by using DORA for DevOps, it's good to consider the following:
- Contextualization: DORA scores need to be put into the context of the company's needs and objectives.
- Data collection and analysis: Collecting the raw data and transforming it into calculable units for DORA scores can be a painstaking process due to the sheer volume of sources.
- DevOps non-linear nature: To avoid false conclusions, turn DORA metrics into KPIs and shift focus to achieving high DORA metric scores.
- Comparing DORA scores for market performance: Measuring market success only through DORA numbers is often pointless—after all, for market performance, the customers and clients will have a final say.
Plus, there are other factors to be considered in DevOps. One such primary concern is security.
The Role of DORA Metrics: Delivery vs. Security
DORA metrics work best for DevOps performance speed and stability. But if you focus only on them to evaluate the software development and delivery process, you may be compromising security.
The security world is ever-changing, and your security measures must adapt, too. Forget about year-long plans and instead focus on agility, software protection, getting the right tools at the right time, and adapting to the ever-shifting market.
DORA metrics don’t adapt to the times, and relying only on them will lead to more bugs and vulnerabilities in the application at later stages. These will, in turn, burden your team with unnecessary workloads, worsen the user experience, and potentially lead to developer burnout.
You and your team can adapt to market changes, especially when combining DORA with value stream management. Value streaming is about continuous improvement—adjusting to customer needs, unforeseen problems, and market opportunities.
A big part of the solution is continuous security: ensuring that your code is protected from development to production.
Following DevSecOps practices, such as implementing shift-left security, will protect against a vicious cycle that harms an organization's productivity and puts software at risk.
» See our solutions for DevOps continuous security
DORA Metrics: Delivering Wins, Securing Doubts
DORA is a stepping stone to high performance and stability in DevOps.
Although DORA metrics improve software delivery, their impact on security can be neutral at best and damaging at worst. A robust DevSecOps practice is a must if you want to compensate for DORA metrics’ missing elements.
How about we simplify continuous security for you?
Jit orchestrates and unifies security tools and controls into all stages of your CI/CD pipeline. When a pull request is created, Jit runs the relevant security tools so your developers can act upon the detected issues using our guidelines or automated remediation.




